
Choosing the Right Device for On-Device AI Inference
Artificial Intelligence (AI) is transforming how machines understand the world, not just in the cloud, but increasingly on the device itself. Instead of streaming every bit of data to remote servers for processing, many systems now make decisions locally, right where the data is created. This trend, often called on-device AI inference, or Edge AI, unlocks real-time responsiveness , greater reliability and better privacy.
But what kind of hardware is actually suitable for running AI models on-device? The answer depends on your application needs, performance goals, latency tolerance, power budget and cost constraints. Let's explore three broad classes of devices, each with its own strengths and tradeoffs.
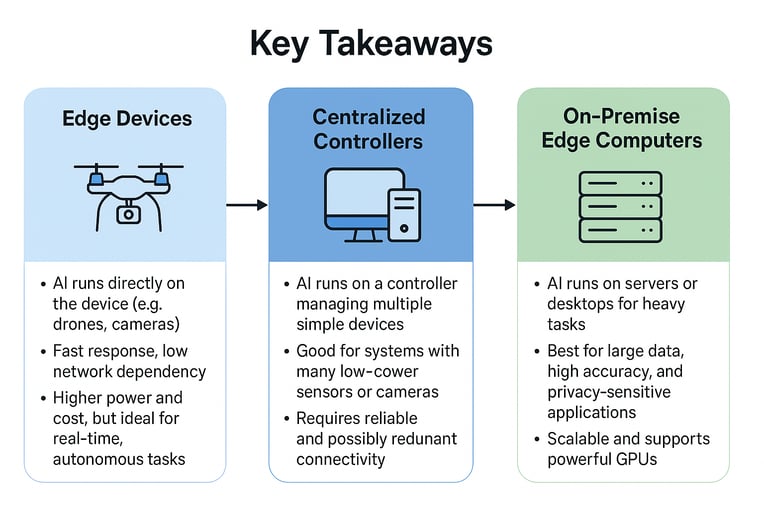
1. Edge devices- Smart, Local AI Everywhere



Edge devices are where AI meets the "real world": drones, smart cameras, robots, sensors, and handeheld tools to name a few. Imagine a surveillance camera detecting unusual activity instantly without waiting for cloud connectivity. That's the power of local inference.
Why choose this approach?
- Fastest possible response : no network delay, decisions happen in milliseconds
- Greater reliability: works even if connectivity is poor or disconnected
- Lower network load: Only essential data needs to be sent upstream
Possible tradeoffs:
- More demanding hardware (AI-capable System on Chips (SoCs) or microcontrollers with NPUs)
- Higher power consumption and cost compared to simple sensors
- Limited by processing and memory budgets
Who benefits most?
Systems requiring real-time decisions and independence from cloud connectivity, such as drones, mobile robots (AGVs/AMRs) defect-detecting cameras, and portable medical devices.
2. Centralized controllers: Coordinating Many Devices


 As systems grow, you may have many simple endpoints, tiny sensors, low power cameras, small actuators that individually lack AI capability. In these cases, a central AI controller (an industrial PC, advanced PLC, or gateway) aggregates data and runs inference for the entire networks.
As systems grow, you may have many simple endpoints, tiny sensors, low power cameras, small actuators that individually lack AI capability. In these cases, a central AI controller (an industrial PC, advanced PLC, or gateway) aggregates data and runs inference for the entire networks.
Why this pattern?
- Endpoints stay simple and low-cost
- Heavy AI tasks are handheld by a central, more powerful unit.
- Easier to manage and update models centrally
Important design considerations:
- Data volume & frequency: How much data comes in and how often?
- Number of devices: More endpoints add complexity
- Response latency: Can the system tolerate milliseconds of central processing?
- Network reliability: Connectivity between endpoints and controller must be robust, with redundancy to prevent failures.
Example use cases:
- Industrial automation systems
- Predictive maintenance setups
- Automatic optical inspection (AOI)
- Surgical assistance systems where multiple sensors feed a central inference engine
3. On-premise Edge Computers: When Accuracy and Scale Matter
 Not all workloads fits tiny processors or real-time constraints. When you need high accuracy models, large datasheets, or data privacy, on-premise edge servers (or even powerful desktop machines) may be the right choice.
Not all workloads fits tiny processors or real-time constraints. When you need high accuracy models, large datasheets, or data privacy, on-premise edge servers (or even powerful desktop machines) may be the right choice.
Why use a server or workstation?
- Massive models: large vision, language, or analytical models often exceed the capacity of small SoCs
- High-precision inference: FP32 or large parameter models run better with plenty of compute and memory
- Data privacy: sensitive information never leaves the local network
- Expandable hardware: You can GPUs, TPUs, or other accelerators for compute-heavy tasks.
Ideal tasks include:
- AI assisted medical imaging analysis
- Genomic data processing
- Early drug discovery
- Generative or agentic AI workflows hosted locally
How to Choose: A Practical Framework
The landscape of on-device AI is not one-size-fits-all, it's a spectrum. Tiny sensors with simple models live alongside powerful servers running large neural networks. What's been consistent is this: AI performs best when its architecture matches both the real-world constraints and goals of the application.
Today's hardware ecosystem, from efficient NPUs in SoCs to centralized AI gateways and on-premise AI clusters, gives designers a rich toolbox. Your job is to define what intelligence you need, how fast it must act, and where it lives. Match those needs to the right device, and on-device AI will deliver reliable, responsive , and efficient insights exactly where they matter most.